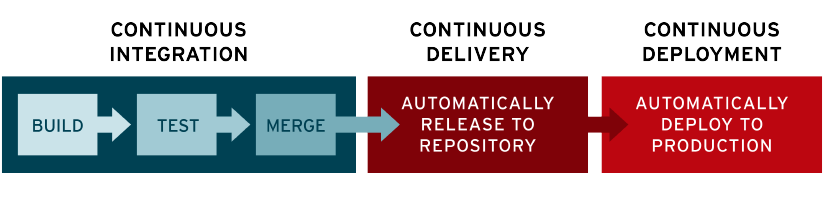
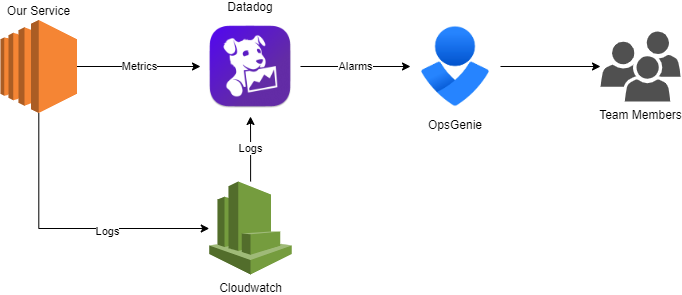
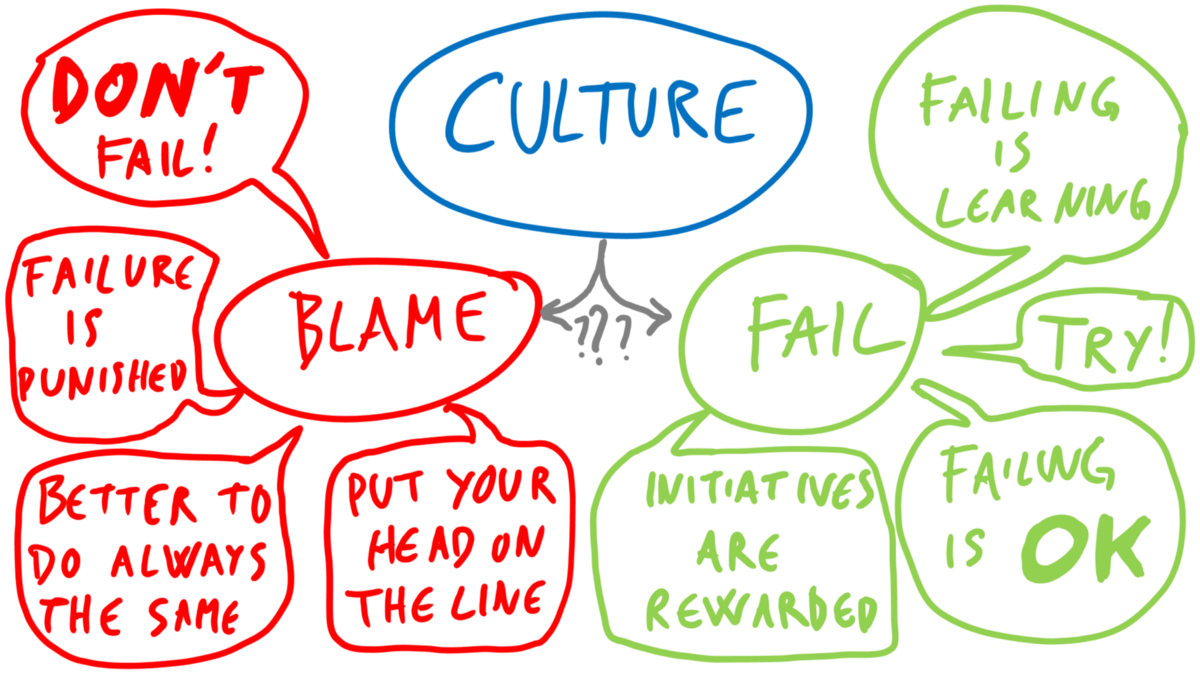
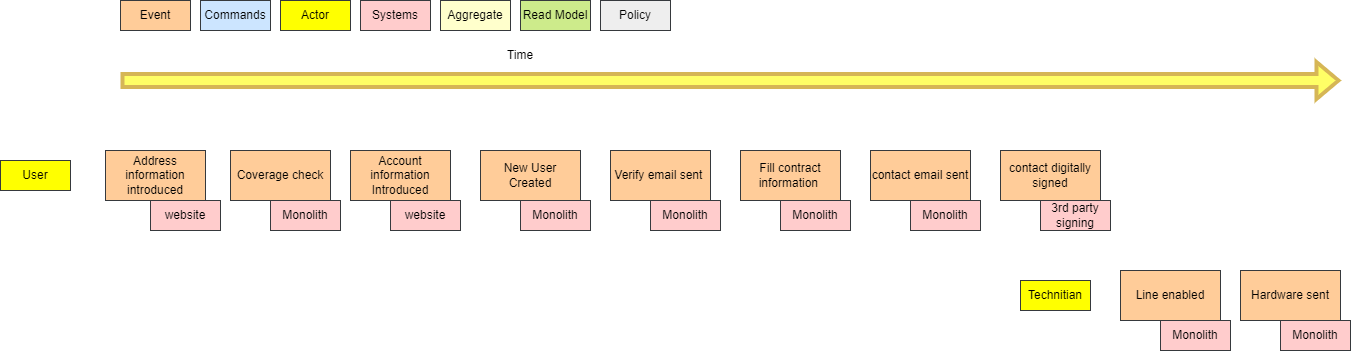
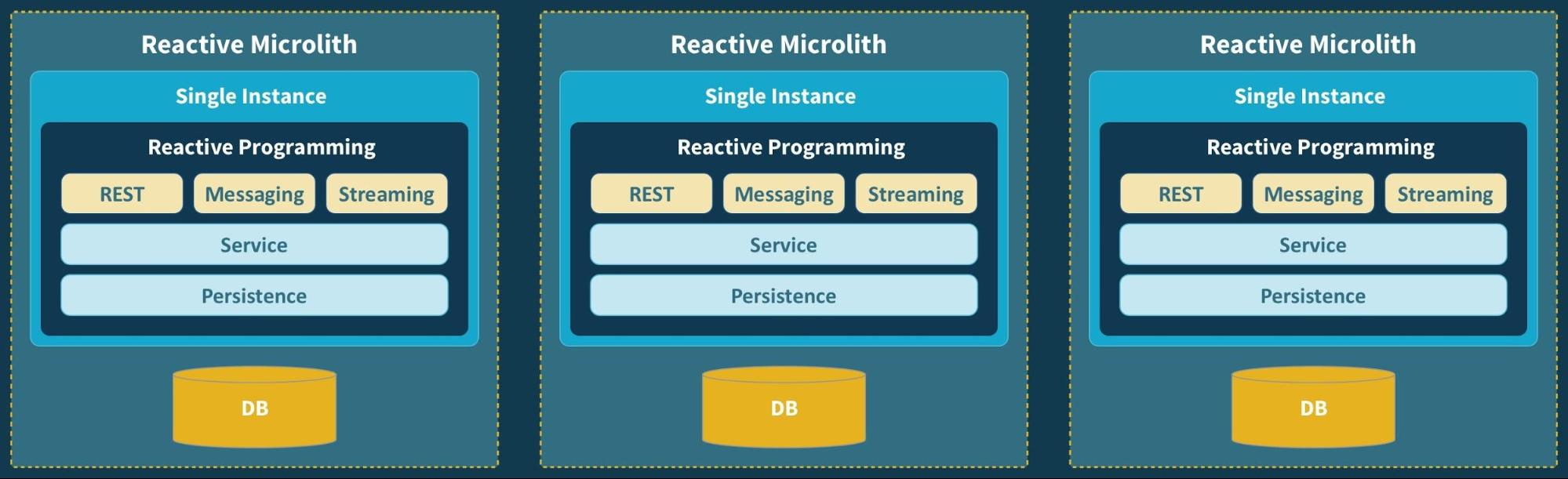
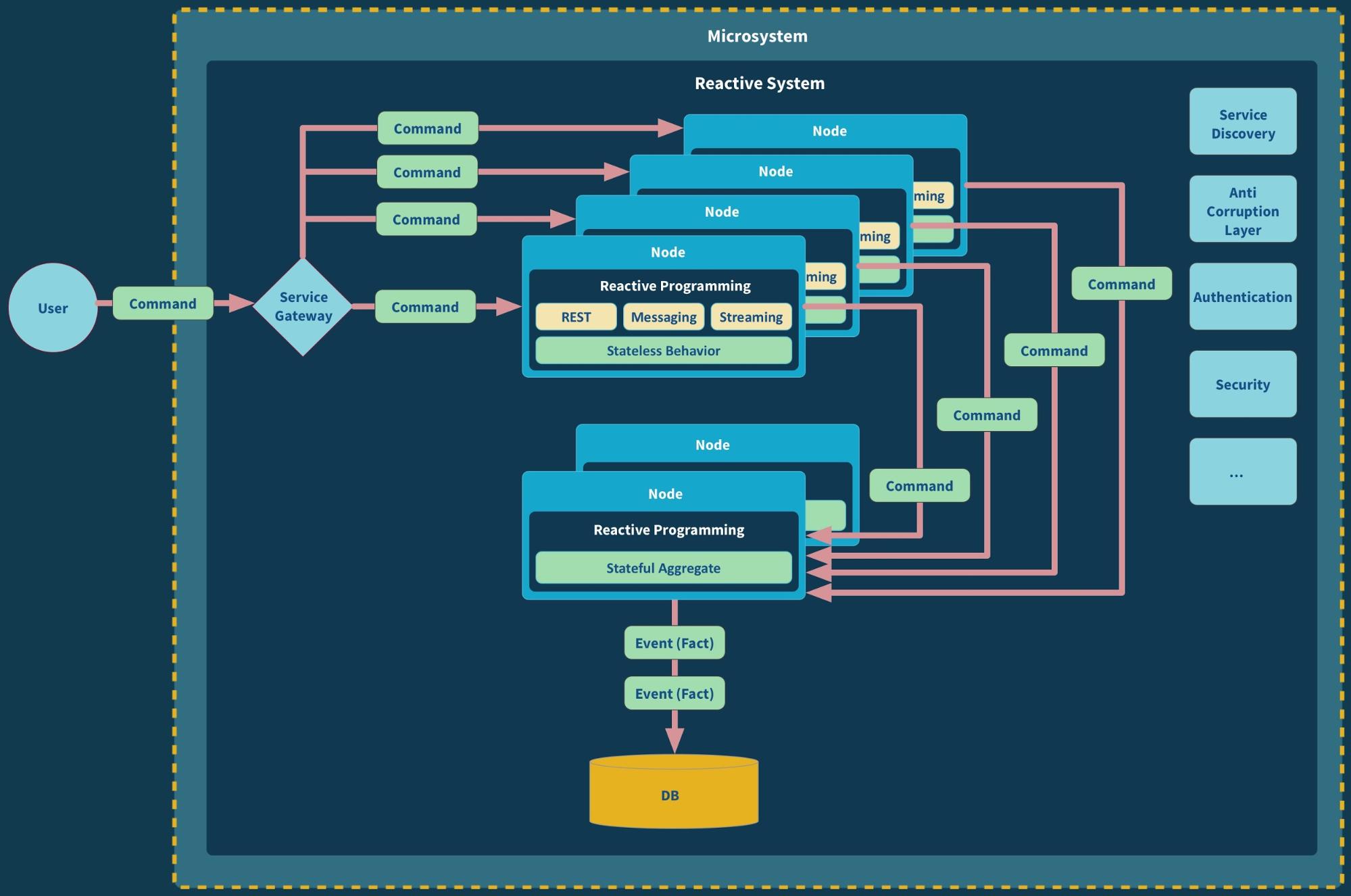
I have already written some other post on this topic. I will go straight to the point on comparing Git Flow (a legacy strategy that most companies use) and Trunk-Based Development.
Gitflow: The Bad & The Ugly
Why do I call it the bad and the ugly? Because it does not allow you to achieve Continuous Deployment.
The idea is that every developer works isolated on their branch, validate on their branch and ask through a merge request to add their code to the X stage branch.
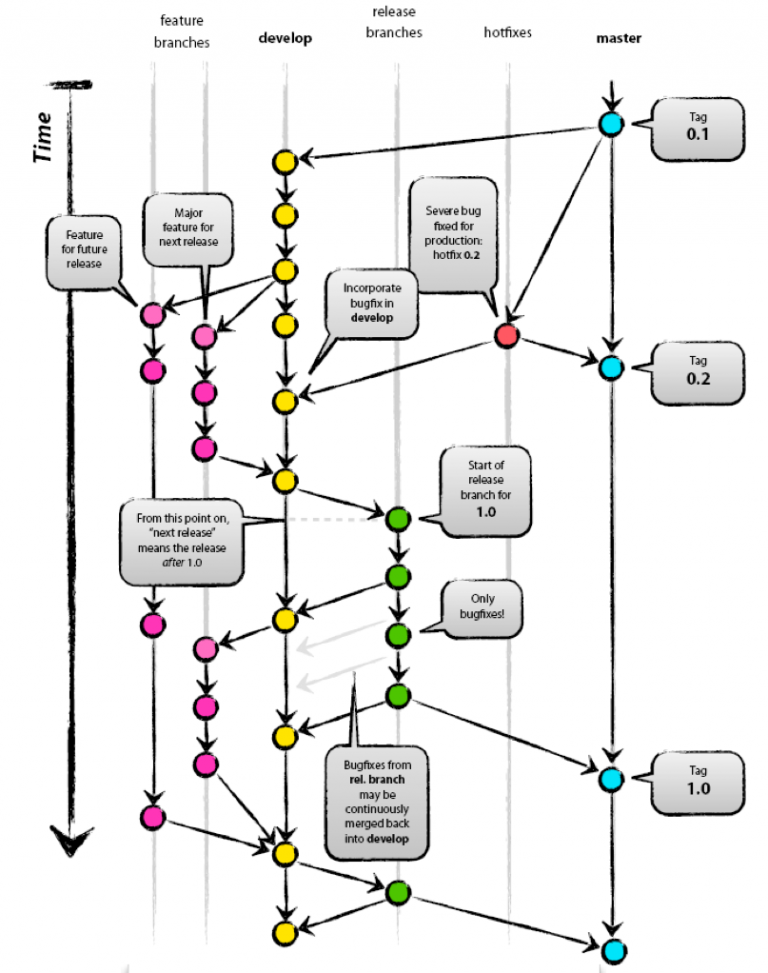
There are multiple issues with this:
- Code does not exist isolated, we don't deploy isolated code, so the isolated test is not valid as it will require retesting.
- The peer review process happens at the end, causing a very slow feedback loop. Having to rewrite code that could be avoided.
- The more time the branch lives, the more it diverges from the original behavior and the more complex it is to merge.
- Merging can cause complex conflicts that require revalidation, and it might have side effect in other features.
- As there needs to be validations of the merges, it's normal to have multiple environments that give a false sense of security, increases the $ cost and increases the lead time.
- Egos and preferences become part of the review process, as it has become an 'accepted' practice that the 'experts' or 'leads' do the reviews.
All of this is red tape to go through is a problem that makes delivery slower, and create a lack of ownership mentality farther away from what happen to the individual branch.
This affects mostly negatively, most of DORA 4 metrics:
- ❌ Deployment frequency
- ❌ Lead Time for change
- ❌ Mean Time To Recovery
Is there a simpler and better way to collaborate on code way?
Trunk-Based Development: The Good
What happens if we all commit to the same branch.
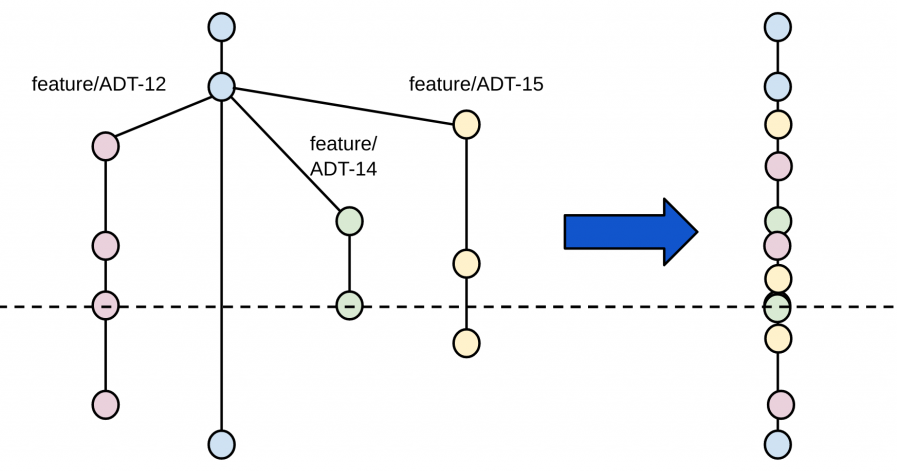
Most of the expressed issues are solved, in this scenario by:
- Code is never isolated, as we all push code to the same place.
- Teams that do this practices also practice pair programming, making the peer review process is continuous and synchronous.
- As individuals push multiple times a day, merge conflicts are non-existent or small.
- Does not require revalidation, as validation is a continuous stream in the single environment.
- No ego environment tent to appear as there is no centralize approver of code, so it's not a matter of preference but a team effort and ownership.
As we have seen before, having unfinished code does not need to affect users, as it is common practice to use feature flags and/or branching by abstraction.
This affect the next DORA 4 metrics:
- ✔️ Deployment frequency
- ✔️ Lead Time for change
- ✔️ Mean Time To Recovery
Conclusion
Simplicity is king. Having a simpler structure enables speed and quality of delivery, as it allow teams to work closely, take shared ownership and act faster related to a smaller change.