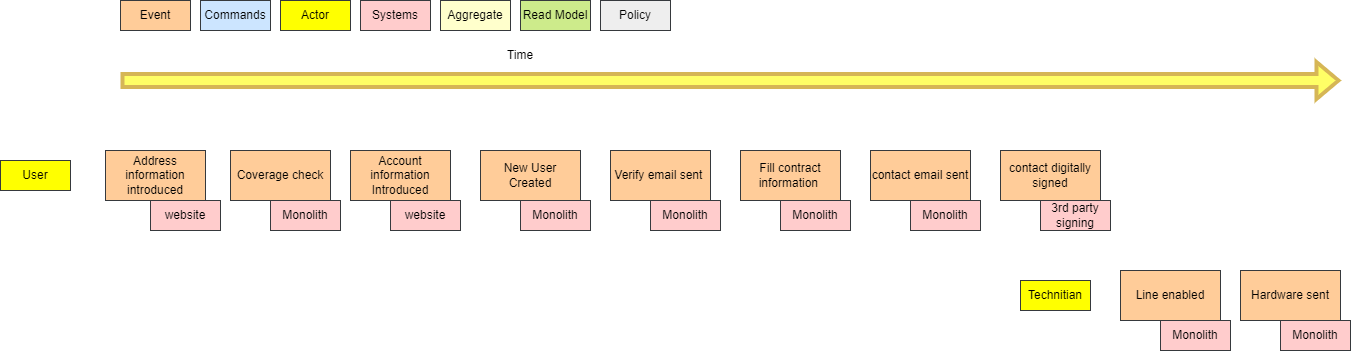
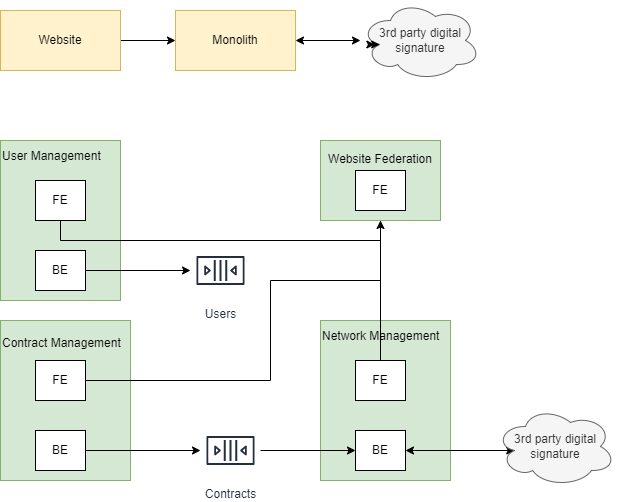
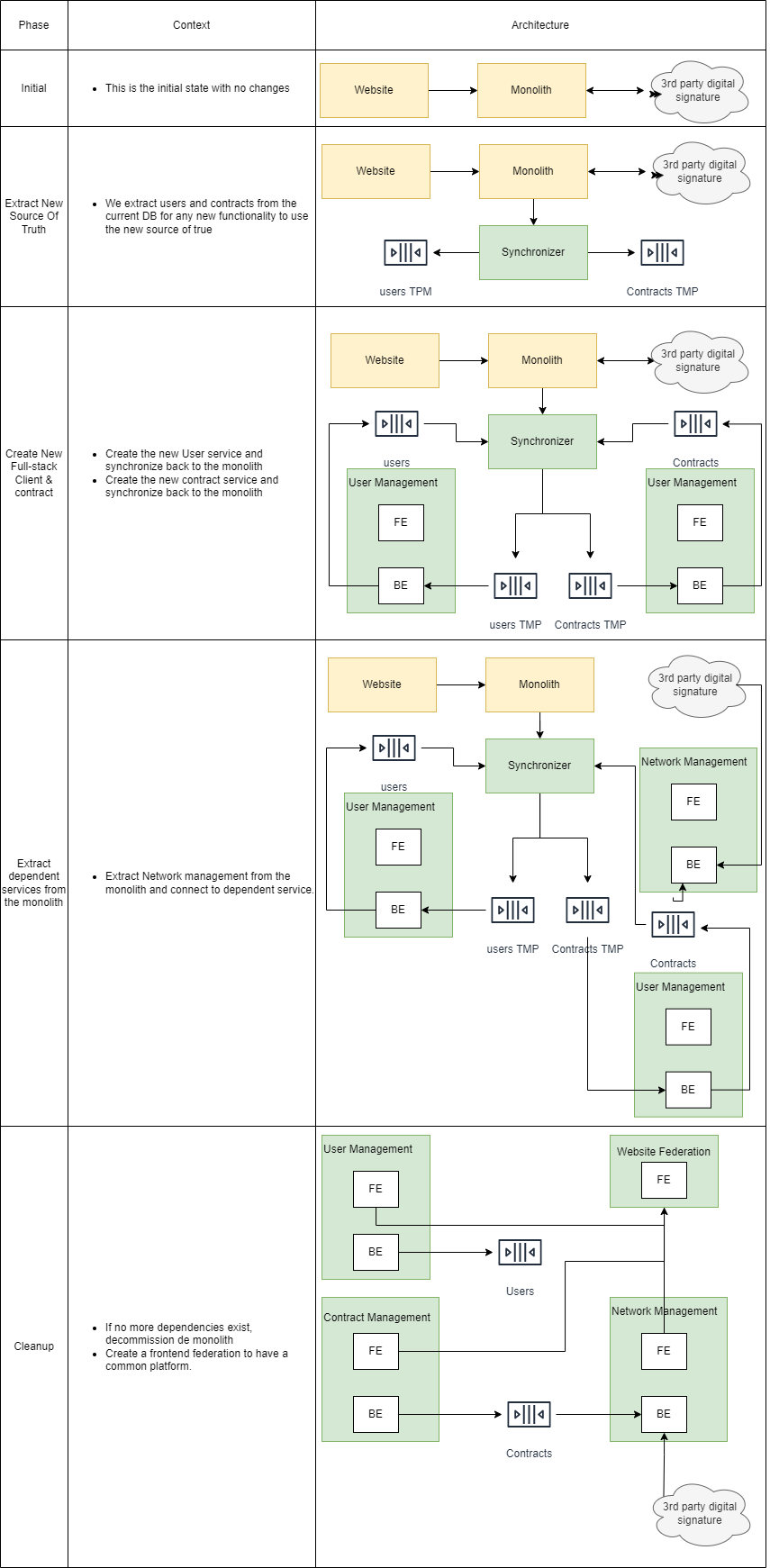
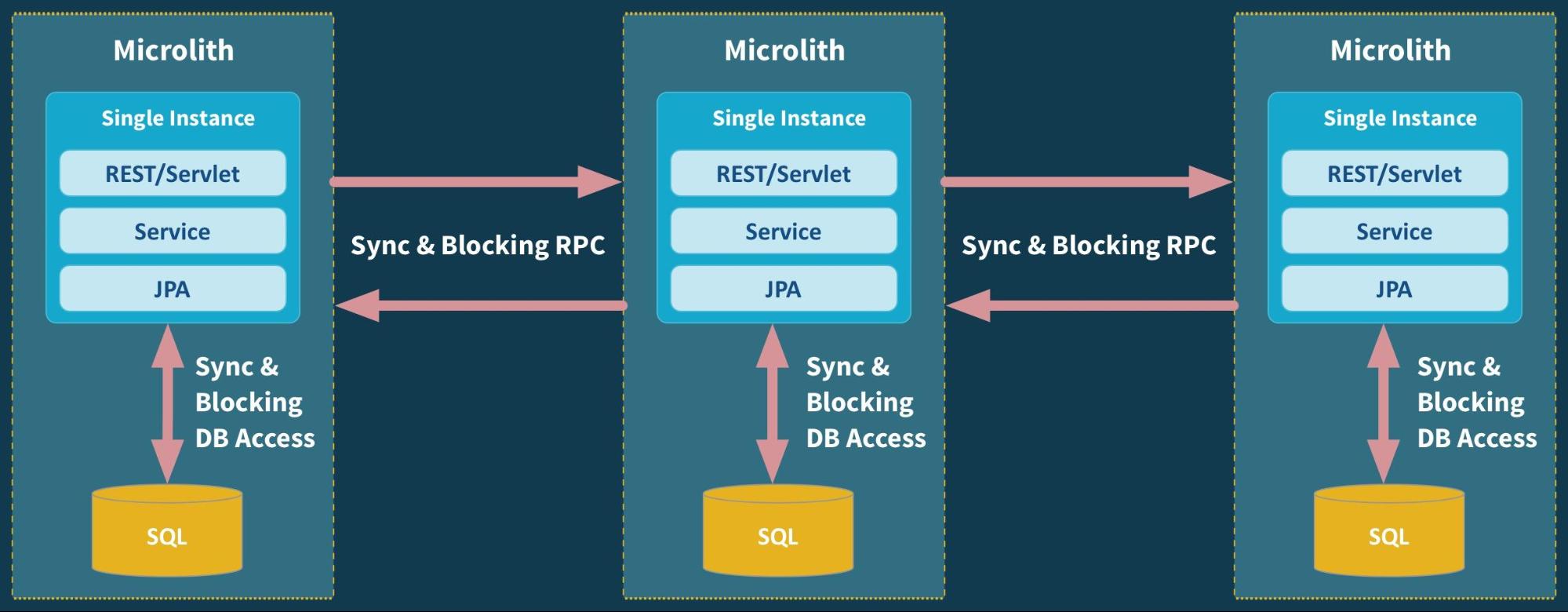
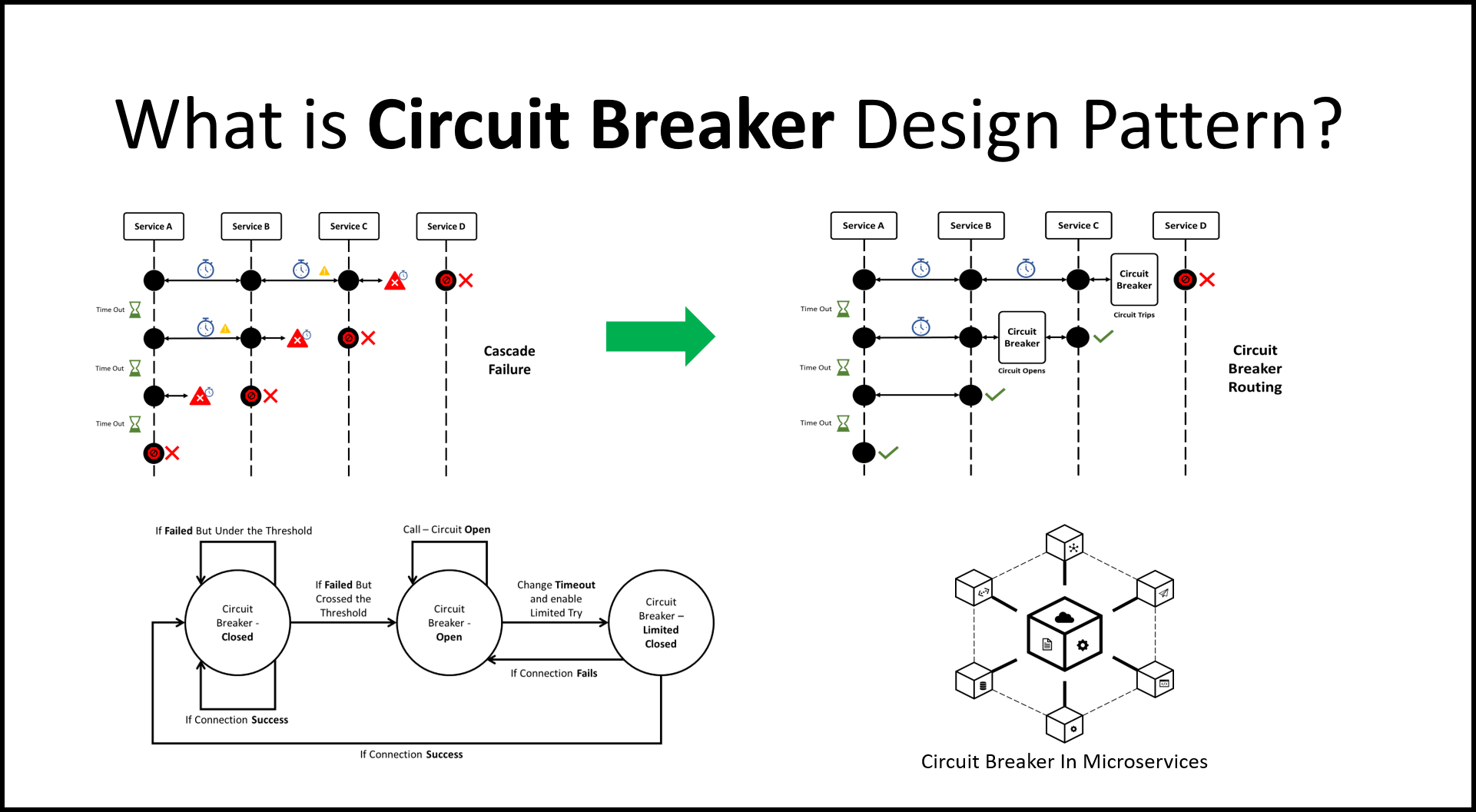
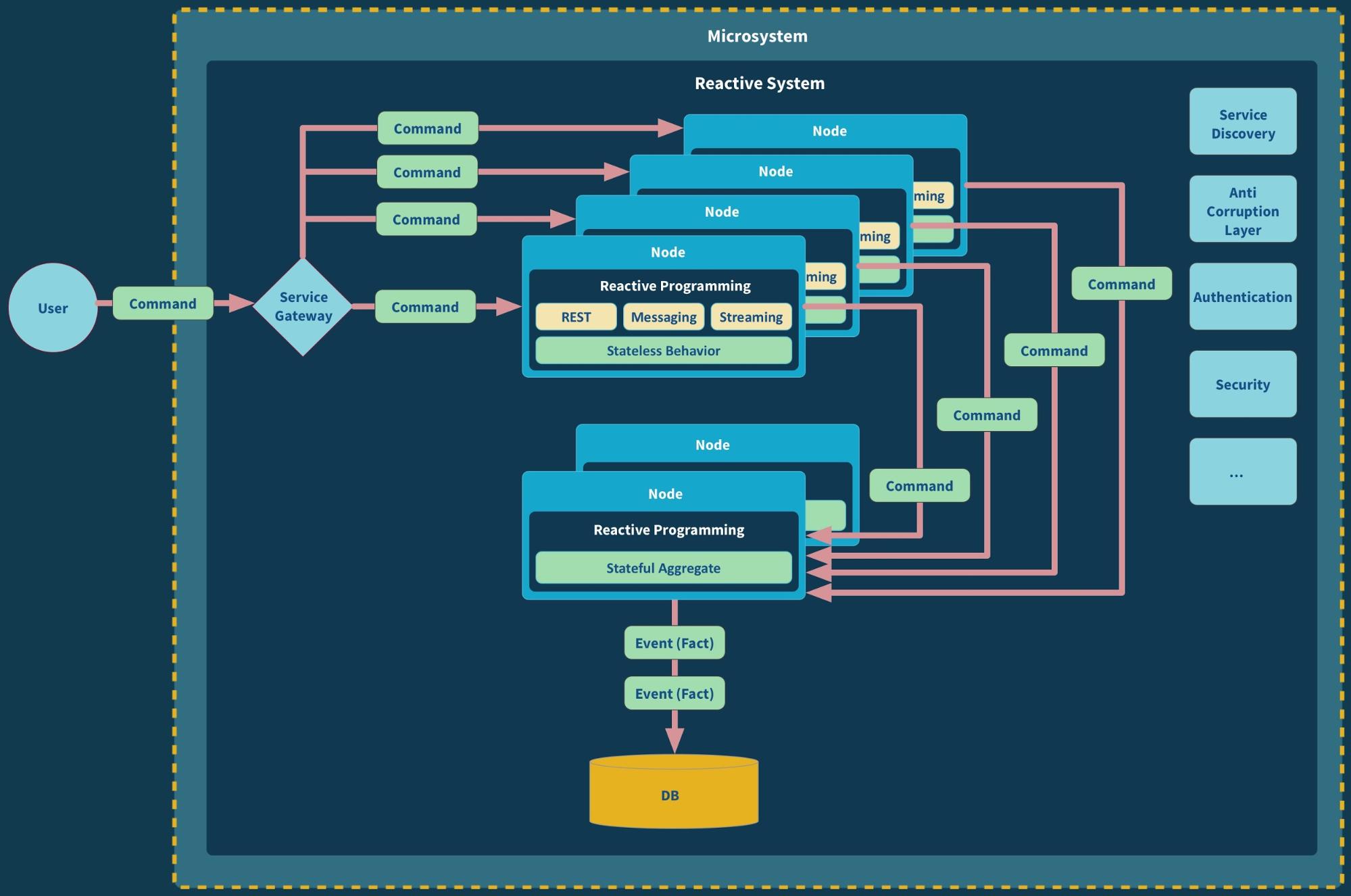
The singleton pattern has got a bad reputation over the years due to be widely overused in the incorrect use cases. With the proliferation of microservices, have APIs become the new singleton?
The Problem
APIs, or application programming interfaces, have become a ubiquitous part of modern software development. They allow different systems and applications to communicate with one another, enabling the creation of complex, interconnected systems that can share data and functionality. However, there has been a growing concern that APIs are being overused, leading to a proliferation of unnecessarily complex and fragile systems that are difficult to maintain and scale.
One reason for the perceived overuse of APIs is the ease with which they can be implemented. With the abundance of API management tools and frameworks available, it is relatively straightforward to expose a set of functionality as an API and make it available to other systems. This has led to a proliferation of APIs, many of which are redundant or unnecessary, adding unnecessary complexity to the overall system.
Another issue is the lack of standardization in the API ecosystem. Each API is typically designed to meet the specific needs of the system it was created for, resulting in a wide variety of different designs and conventions. This can make it difficult for developers to understand and use APIs from other systems, as they may have to learn and adapt to new conventions and patterns each time they encounter a new API.
In addition to these issues, the reliance on APIs can also lead to fragile systems that are difficult to maintain and scale. When multiple systems are tightly coupled through APIs, a change to one system can have cascading effects on others, leading to unexpected behavior and potential failures. This can make it difficult to make changes or updates to a system without the risk of breaking something else.
There are also concerns about the security of APIs. As they allow systems to communicate with one another, they can also provide a potential entry point for attackers to gain access to sensitive data or functionality. Properly securing APIs can be a complex and time-consuming task, and if not done correctly, can lead to significant vulnerabilities.
The Solution
So, what can be done to address these issues? One solution is to use APIs more judiciously, carefully evaluating whether an API is truly necessary before implementing it. This can help reduce the overall complexity of the system and make it easier to maintain and scale.
It's also important to adopt API design standards and guidelines, which can help ensure that APIs are consistent and easy to understand and use. Finally, proper API security practices should be implemented to protect against potential vulnerabilities.