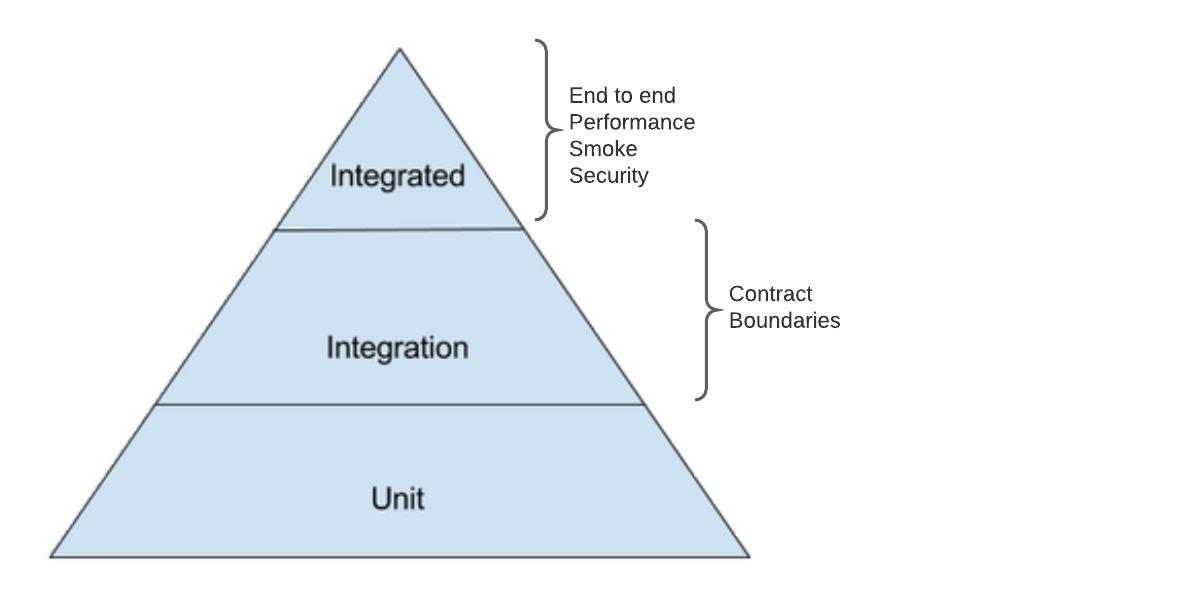
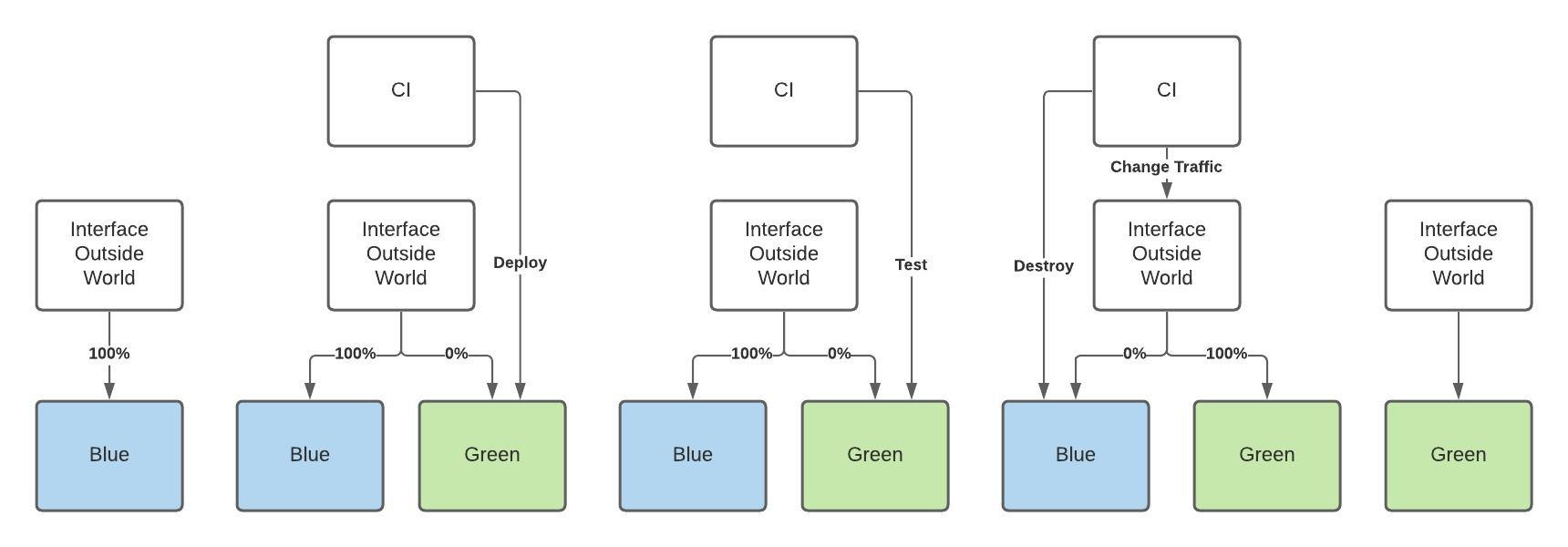
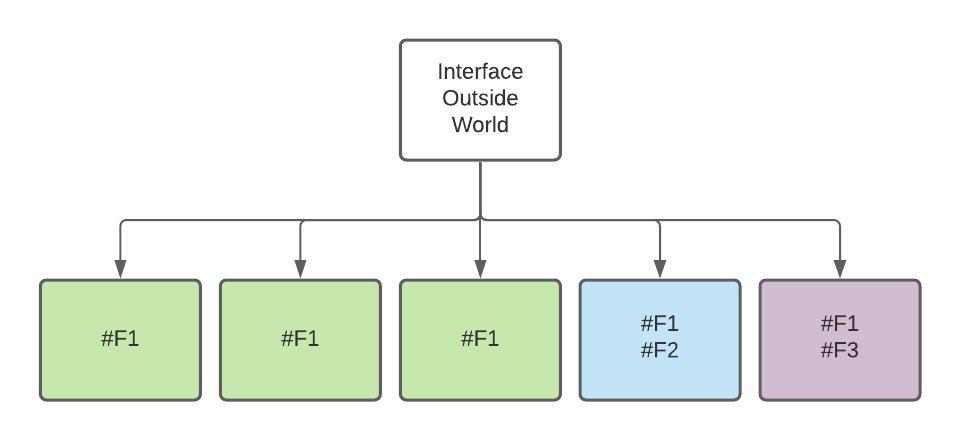
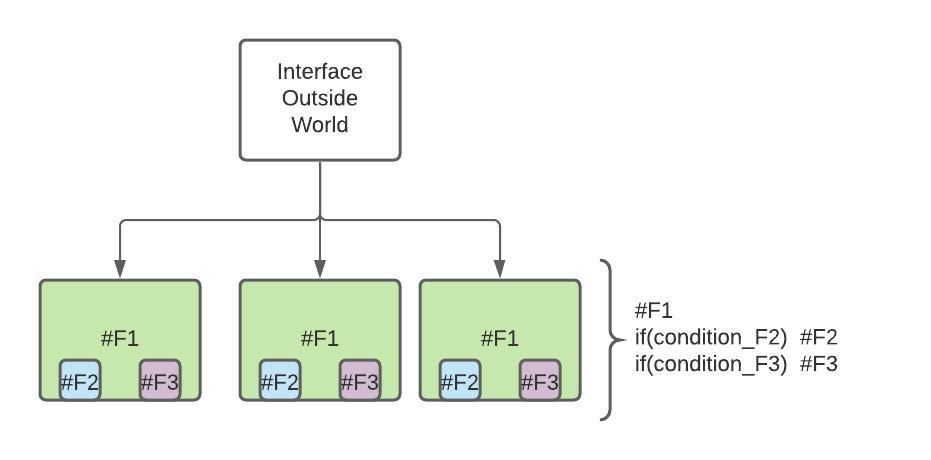
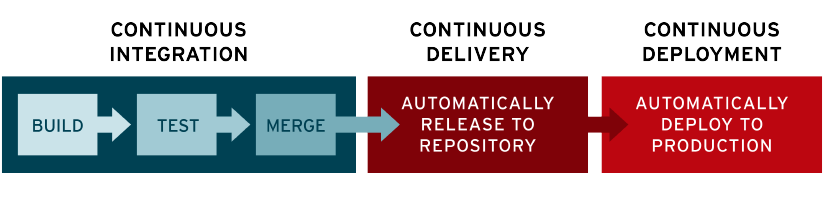
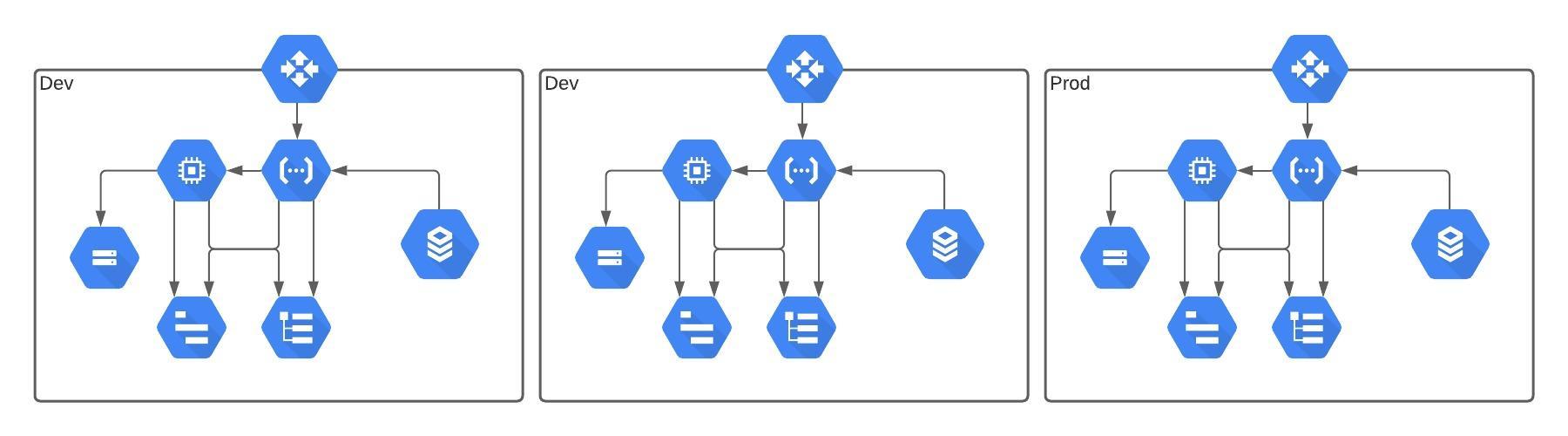
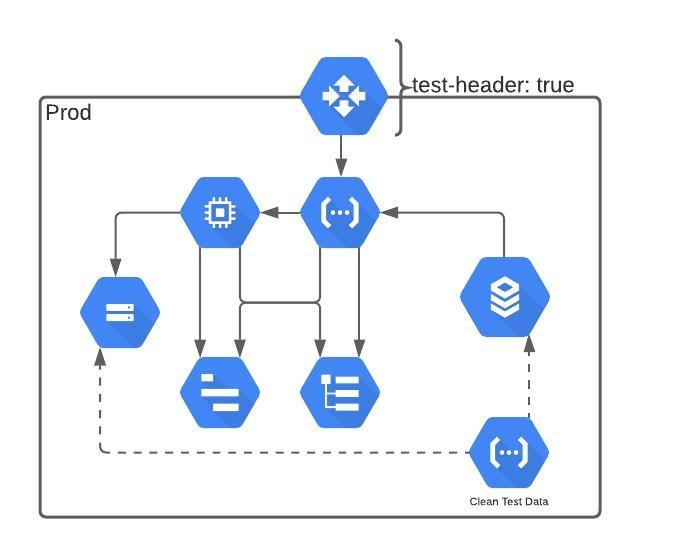
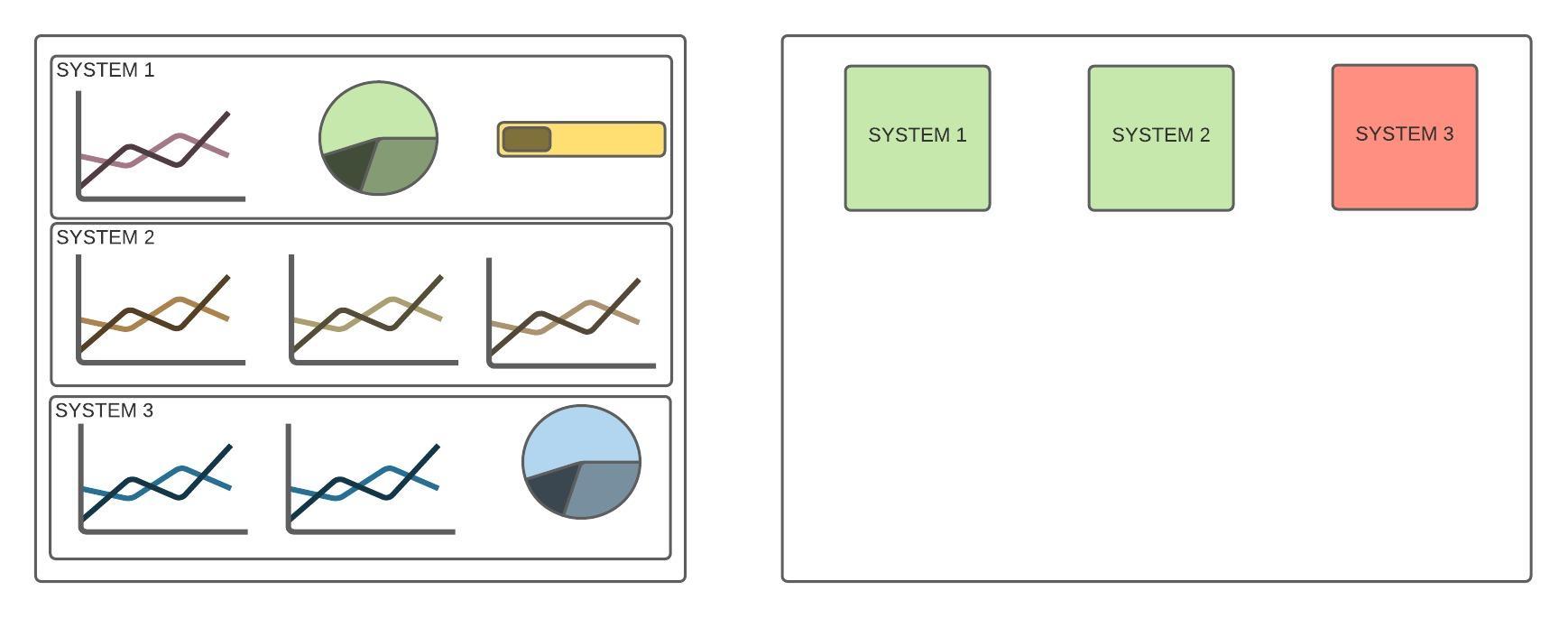
psychological safety is essential for the success of software development teams. By fostering open communication and encouraging a culture of learning and innovation, teams can work more efficiently, effectively, and creatively. By promoting psychological safety, managers and leaders can help their team members to reach their full potential and take the team to the next level.
Long Version
What is psychological safety
Psychological safety refers to the belief that one will not be punished or humiliated for speaking up with ideas, questions, concerns, or mistakes. It is a shared belief held by members of a team that the team is safe for interpersonal risk-taking. This safety allows team members
Why is psychological safety important
Psychological safety is an essential aspect of any successful organization. Software development organizations are no exception.
One of the main benefits of psychological safety is the ability to foster open and honest communication. When team members feel safe to speak up, they are more likely to share their thoughts and ideas, which can lead to more efficient problem-solving and decision-making. In a field that is constantly evolving and where new technologies and approaches are continually emerging, it is essential to stay up-to-date and adapt to change.
Furthermore, it allows for creativity and innovation to flourish. When team members feel secure in their ability to express themselves, they are more likely to think outside the box and come up with new and unique solutions. In software development, this can be the difference between the success and failure of a project.
However, creating a culture of psychological safety is not always easy. It requires active effort and commitment from everyone on the team, including managers and leaders. One important step is to actively listen to and encourage open dialogue among team members. Managers should also create an environment where mistakes are viewed as opportunities for learning, not as failures.
Another important step is to establish clear guidelines and expectations for communication and behavior within the team. This can include things like setting ground rules for respectful dialogue and providing training on active listening and conflict resolution.
Finally, it is essential to hold every one on the team accountable for maintaining a culture of psychological safety. This includes managers, who should lead by example and model the behavior they expect from their team.